



From AI Clusters to 800G Transceivers: Designing High-Performance Networks for the AI Era

AI Clusters vs Traditional Data Center Clusters: A Shift in Network Architecture
CPU-Centric vs XPU-Centric Design
AI clusters are different from traditional data center clusters at the network architecture. CPU servers are at the core of traditional data centers, and their design for communication is based on horizontal communication between access to the configuration node to the storage node and finally to the computing node. The overall traffic pattern is fairly distributed and balanced, and the network plays more of a connector role with less need for extreme bandwidth or latency requirements.
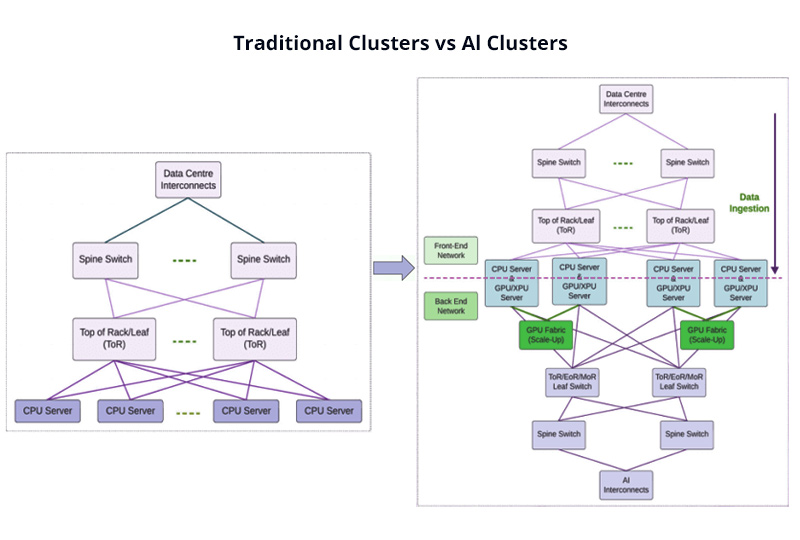
In contrast, AI clusters are gradually shifting towards an architecture centered around XPUs. To accommodate the demands of large-scale model training and parallel computing, their networks are clearly divided into two layers: a Frontend Network, primarily handling communication between CPUs and between CPUs and storage, functionally similar to a traditional data center; and a Backend Network, dedicated to high-speed interconnection between XPUs. This latter part has extremely high requirements for bandwidth, latency, and consistency, often directly determining overall training efficiency, and is precisely where ultra-high-speed interconnects such as 800G modules become essential.
Network Requirements of AI Clusters
Extreme Scale
AI clusters first face the challenge of explosive growth in scale. To support the training of large models, the network needs to support elastic scaling from a single rack to across data centers, with the number of computing nodes often reaching hundreds of thousands or even millions. In this context, the network not only needs to have high-density access capabilities, but also needs to maintain stable performance during large-scale expansion to avoid problems such as congestion, packet loss, or uneven performance as the scale increases.
High Efficiency and Ultra-Low Latency
During AI training, nodes need to communicate frequently. This type of communication is extremely sensitive to latency, typically requiring microsecond-level latency, while also needing to be as close to full bandwidth utilization as possible, usually above 90%. Insufficient network efficiency or latency fluctuations will directly slow down the overall training progress. Therefore, high efficiency and ultra-low latency have become core indicators for AI network design.
Flexibility
Apart from performance, another important demand is flexibility for the AI cluster networks. Real-world deployments often need to support XPUs from different vendors. If the network lacks sufficient adaptability, the overall computing power can be limited by the weaker performance of some nodes. Therefore, the network needs excellent compatibility and scheduling capabilities to achieve efficient resource coordination and maximize overall performance.
Main Network Design Paradigms for AI Cluster Architectures
Endpoint-Scheduled Architecture
The core concept of this architecture is to place all scheduling intelligence at the endpoints, such as NICs, DPUs, or IPUs, while the network fabric itself is only responsible for basic packet forwarding, essentially serving as an optimized extension of traditional Ethernet. In terms of topology, it typically adopts a classic flattened Spine-Leaf or Super-Spine Clos architecture, where switches only need to support high radix and 800G ports. Because scheduling responsibilities are shifted to the endpoints, the NICs must support Dynamic Load Balancing (DLB), Adaptive Routing, packet spraying, and end-to-end congestion control. Its simple architecture, flexible cabling and complete compatibility with the existing Ethernet ecosystem makes this design suitable for small‑ to medium‑sized clusters. But its downsides are evident: The vendor lock‑in based on NIC layers is significant, and scheduling complexity at extremely large scales causes susceptibility to load imbalance and hot spots in the network.
Switch-Scheduled Architecture
This architecture completely offloads the scheduling responsibilities from endpoints to the network switches. The endpoints can utilize commodity NICs, and the fabric provides lossless, high-performance data transport using cell-based switching and credit-based flow control. The advantages of this architecture are its NIC vendor agnosticism, extremely stable performance at ultra‑large scales, and precise congestion control. Its main drawbacks are the higher hardware complexity and cost of the switches, as well as the need for cabling to be specifically aligned with the requirements of cell switching.
Topology and 800G Interconnect Choices for AI Clusters
Multi-Plane Architecture for Large-Scale Scaling
In order to scale AI clusters, Multi-Plane architecture has become a widely adopted approach. In this design, each plane operates as an independent Spine-Leaf fabric, typically supporting 4K–10K XPUs. These planes run in parallel and are interconnected through an upper-layer aggregation mechanism.
Using multiple planes in parallel, would allow clusters to scale up almost linearly. In fact, even with 10 planes or so the entire system can easily grow beyond 100K XPUs. Simultaneously, per-plane independence permits very good fault isolation and will help with linear bandwidth scaling as the cluster grows.
Selecting 800G Interconnects by Deployment Scenario
Intra-Rack (≤7m)
Within a single rack, where devices such as switches, GPUs, and servers are closely positioned, the most cost-effective solution is 800G DAC. For lengths of 2–3 meters passive DAC cables are most common, provide ultra-low latency and are the lowest cost. For such longer inter rack connections ranging to about 7 meters, active DAC is recommended. These are popular solutions for use within AI training clusters, where high port density and low power consumption is key.
Intra-Row / Short-Reach (≤50m)
When it comes to connections between racks in the same row, flexibility and cabling management take precedence. It is common to deploy 800G AOC in this range, which has relatively stable performance and low power consumption. In addition, optical modules such as 800G SR8, which supports transmission distances of up to 50 meters over multimode fiber with dual MPO-12/APC interfaces, are well suited for short-reach structured cabling.

Medium-Reach (≤500 m)
When the transmission distance is 500 meters or less, you can choose the 800G DR8 module, which supports up to 500 meters over single-mode fiber. In addition, 800G 2DR4 modules offer deployment flexibility, especially in breakout scenarios, such as 800G to 2x 400G breakout connectivity and 800G to 8x 100G breakout connectivity. These modules are ideal for spine-to-spine or leaf-to-spine interconnections in large-scale cloud and AI data centers.
Long-Reach (2km–10km)
For inter-building, intra-campus, or metropolitan data center interconnection scenarios, it is typically necessary to select 800G optical modules that support longer transmission distances. Within a transmission range of approximately 2 kilometers, the 800G 2XDR4 is one of the common solutions; this module uses two MTP/MPO-12 interfaces for single-mode transmission and supports a maximum connection distance of 2 kilometers. Meanwhile, the 800G 2FR4 is a mainstream choice. It transmits data via duplex single-mode LC fibers, achieving a maximum transmission distance of 2 kilometers.
For connections up to 10 kilometers, 800G LR8 optical transceivers are usually employed. These modules typically featured uplex LC interfaces,providing fine suitability with current fiber networks while sustaining dependable operation across greater spans.
Conclusion
In the AI era, networks have evolved from being merely a connectivity layer to becoming a core driver of computing performance. As architectures shift towards XPU-centric designs, it is essential to choose the right network paradigm, scalable topology and 800G interconnects to ensure high efficiency, low latency and future-ready scalability for AI workloads.





share

